
Künstliche Intelligenz in der Qualität – Bestehendes Know-how effektiv nutzen

Viele Branchen sind heute mit stetig steigenden Qualitätsanforderungen konfrontiert. Zusätzlich erfordern komplexere Produkte erweiterte Absicherungen im Herstellungsprozess. Gleichzeitig stehen viele Hersteller vor der Herausforderung, Kostenoptimierungen umzusetzen, um langfristig wirtschaftlich zu bleiben. Wie kann Qualität diesen Spagat schaffen?
Neue Methoden im Bereich der künstlichen Intelligenz (KI), insbesondere des Machine Learnings bieten Möglichkeiten, um Verbesserungspotenziale auf Basis bestehender Daten zu heben. Besonders bei komplexen Produktionsabläufen kann Machine Learning zu neuen Erkenntnissen führen. Für Praktiker stellt sich allerdings die Frage, wie sich neue Methoden sinnvoll in bestehende Arbeitsabläufe integrieren lassen.
Dieser Beitrag zeigt auf, dass es große Überschneidungen zwischen klassischen Q-Werkzeugen und modernen KI Methoden gibt. Machine Learning, als Unterdisziplin der KI, wird den Methodenkoffer der Qualität langfristig erweitern. Der Beitrag nennt darüber hinaus Erfolgsfaktoren für Mitarbeiter und Führungskräfte, die Machine Learning in ihrer Firma einsetzen wollen, um ihre Prozesse effizienter zu gestalten.
Machine Learning als Prozess und Methode
Der Einstieg in den Bereich des Machine Learnings gestaltet sich in der Qualität wesentlich einfacher als in anderen Ressorts. In Abbildung 1 ist ein Vergleich der Methoden des PDCA-Zyklus, der Six Sigma DMAIC Methode und der IBM Data Science Methode dargestellt. Die Abbildung zeigt die Parallelen der Ansätze.
Alle drei Methoden verfolgen das gleiche Ziel: Nachhaltige Lösung eines bestimmten Problems.
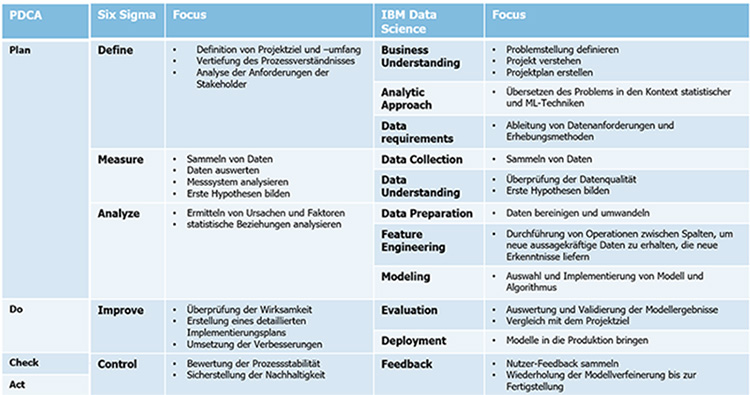
Abb. 1: Vergleich zwischen PDCA, Six Sigma DMAIC und IBM Data Science Methode
Machine Learning und klassische Qualitätswerkzeuge basieren grundsätzlich auf Methoden der Statistik (induktive, deskriptive und explorative Statistik). Hier zeigen sich ebenfalls große Überschneidungen zwischen den beiden Ansätzen. Somit ist das Grundwissen für Machine Learning in vielen Qualitätsbereichen bereits vorhanden.
Auch prozessseitig gibt es große Parallelen zwischen KI-Projekten und dem klassischen Qualitätswesen. KI-Anwendungen lassen sich durch das Turtle Modell beschreiben (vergleiche Abbildung 2). In diesem Fall liegt der Fokus auf Dateneingabe, Verarbeitung mit Generierung der wertschöpfenden Informationen und Datenausgabe. Der Ansatz ist jedoch gleich.
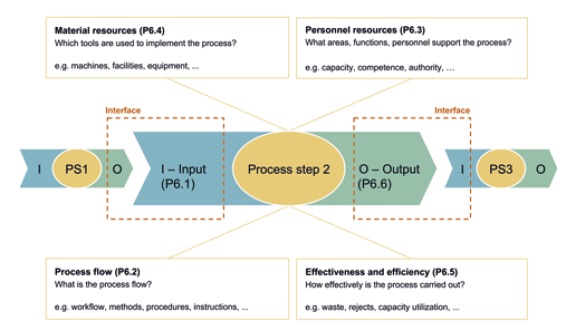
Abb. 2: Turtle-Modell nach VDA 6.3 (2023)
Was bleibt ist die Frage, wie eine gute Umsetzungsstrategie aussehen kann, um die neuen Machine Learning Werkzeuge im Unternehmen einzuführen. Eine der größten Hürden bei der Nutzung von Machine Learning besteht darin, Daten in geeigneter Art und Weise für die Mitarbeiter bereitzustellen. Hierbei kommt den Führungskräften eine Schlüsselrolle zu.
Datenverfügbarkeit und Dokumentation
Führungskräfte haben großen Einfluss darauf, wie und in welcher Form Daten abgelegt werden. Es gilt darauf achten, dass von vornherein möglichst nur maschinenlesbare Daten erzeugt werden.
Folgende Prinzipien helfen dabei, dieses Ziel zu erreichen:
- Standardisierung der Daten mit einem einheitlichen Datenmodell
- Nutzung von Datenbanken als Datenablage
- Wenn keine Datenbank verwendet werden, sind einfach interpretierbare Dateiformate (z.B. csv oder xml) sinnvoll
- Für Prozessdokumentation sollten feste Formulare mit möglichst wenig Freitext gewählt werden.
Die zweite Aufgabe für Führungskräfte besteht darin die Daten verfügbar zu machen. Es müssen Schnittstellen geschaffen werden, über die die Mitarbeiter sicher auf Daten zugreifen können. Dabei muss sichergestellt sein, dass eine fehlerhafte Abfrage nicht zu ungewolltem Datenverlust führen kann. Dies ermöglicht einen spielerischen Umgang mit Daten ohne Risiko. Anschließend sind die Mitarbeiter an der Reihe diese Daten gewinnbringend zu nutzen.
Auswahl geeigneter Anwendungen
Eine wichtige Aufgabe der Qualität war es seit jeher Transparenz zu schaffen und Optimierungspotenziale aufzudecken. Diese Aufgabe wird im Datenzeitalter noch wichtiger. Der Umgang mit Daten wird in Zukunft eine grundlegende Anforderung an Mitarbeiter im Qualitätswesen sein. Es ist jedoch nicht realistisch, alle Qualitätsmitarbeiter auf das Qualifikationsniveau von Datenspezialisten zu heben. Dies ist aber auch nicht nötig. Der Schlüssel zum Erfolg liegt in einer geeigneten Auswahl von Softwarewerkzeugen.
No-Code/Low-Code Lösungen, wie KNIME oder Tableau, bieten einfache Möglichkeiten, die Einstiegsschwelle für Mitarbeiter zu senken und schnellen Mehrwert zu schaffen. Grafische Visualisierungen und Dashboards stellen dabei einen guten Einstieg in die Welt des Machine Learnings dar. Dashboards können beispielswese gleichzeitig Auskunft über verschiedene Kennzahlen (z.B. Stillstandszeiten, OEE oder Ausschuss) geben und lassen sich gut in tägliche Shopfloormeetings einbinden. Es werden keine Programmierkenntnisse benötigt, um einfache Dashboards zu erstellen. Die Anleitungen sind meist frei im Internet verfügbar und viele Werkzeuge können kostenlos verwendet werden. Entscheidend für den erfolgreichen Einsatz von Dashboards ist, dass die Daten nicht mehr von Hand eingepflegt werden. So können die Mitarbeiter sich auf die Lösung der Probleme konzentrieren. Dies erhöht die Akzeptanz und motiviert die Mitarbeiter nach weiteren Anwendungen zu suchen. Der Übergang zum tatsächlichen Machine Learning (zum Beispiel durch Erweiterung von Dashboards für Klassifikation und Prognosen) ist fließend.
Ein weiteres Themenfeld für einen einfachen Einstieg sind Sprachmodelle. KI-Werkzeuge wie ChatGPT können Daten und Texte schnell zusammenfassen oder Fragen zu den Eingangsdaten beantworten. Sprachmodelle benötigen ebenfalls keine Programmiererfahrung und eignen sich hervorragend für Einsteiger. Interessant sind Sprachmodelle auch deshalb, weil sie sich einfach anpassen und mit anderen Systemen verknüpfen lassen (zum Beispiel automatische Terminbuchungen im Kalender oder Erfassung von Kundenreklamationen). Folgender Link zeigt ein angepasstes Sprachmodell, welches Fragen zu ISO 9001 oder IATF 16949 beantwortet. Sprachmodelle und Datenverarbeitung werden in den nächsten Jahren noch sehr viel enger zusammenwachsen. Beispiele hierfür sind Copilotfunktionen, die den Benutzer bei seiner Arbeit unterstützen und für Microsoft Windows und Office bereits erprobt werden.
Was die Zukunft bringt
Wir gehen davon aus, dass Programmierkenntnisse durch weitere Verbreitung von Copiloten und Low-Code/No-Code Werkzeugen an Bedeutung verlieren werden. Machine Learning wird damit für mehr Mitarbeiter ohne Programmierkenntnisse einsetzbar.
Im Zuge dieser Entwicklung werden immer mehr Methoden des Machine Learnings (Clustern, Klassifikation, Regression oder Prognosen auf Basis von Modellen) in den Methodenkoffer des Qualitätswesens integriert werden. Die grundlegende Arbeitsweise des Qualiätswesens nach PDCA und DMAIC bleibt dabei erhalten. Die neuen Werkzeuge aus dem Bereich Machine Learning versprechen schnellere Problemlösung und hohe Transparenz. Mitarbeiter, die heute noch händisch Daten erfassen und verarbeiten, werden entlastet und können so weitere Verbesserungen für das Unternehmen erzielen.
Unternehmen können diese Entwicklung aktiv fördern, indem sie die Datenqualität und Datenverfügbarkeit verbessern (siehe Abbildung 3). Mitarbeiter sollten spielerisch an Datenverarbeitung und Machine Learning herangeführt werden und ihre intrinsische Motivation sollte durch geeignete Schulungen aktiv unterstützt werden. Der Fokus für Qualifikation sollte dabei darauf liegen die Methoden des Machine Learnings zu kennen und diese Methoden mittels Low Code / No Code Lösungen im Unternehmenskontext einzusetzen.
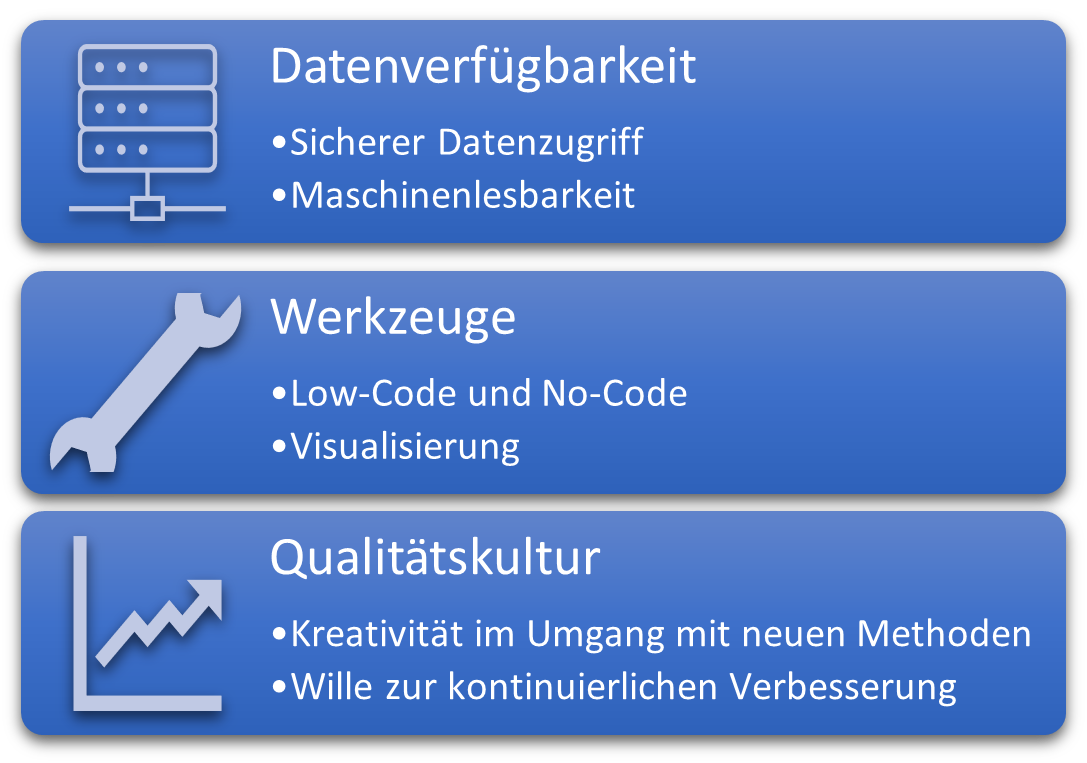
Abb. 3: Übersicht der Erfolgsfaktoren für moderne Qualitätsarbeit
Lesen Sie auch die beiden anderen Teile der Reihe “Künstliche Intelligenz in der Qualität“:
- Teil 2: Künstliche Intelligenz in der Qualität – Welche Qualifikationen werden benötigt? – zum Beitrag »
- Teil 3: Künstliche Intelligenz in der Qualität – Praktische Einführung durch iteratives Vorgehen – zum Beitrag »
Über die Autoren:
Dipl.-Ing. Waldemar Fahrenbruch ist Head of Q-Technology Division E-Mobility bei der ZF Friedrichshafen AG. Er ist verantwortlich für die Qualitätskostensenkung bei gleichzeitiger Optimierung von Qualitätskonzepten in den Werken der Division E (TCU, Power Electronics und E-Motoren Fertigung) durch Methodenkompetenz der Qualität, künstlicher Intelligenz und digitaler Transformation.
Dr.-Ing. Stefan Prorok ist Geschäftsführer der Prophet Analytics GmbH und DGQ-Trainer für Qualitätssicherung und Prüfmittel.
Rollins, John. “Why we need a methodology for data science.”, IBM Analytics Whitepaper (2015). https://tdwi.org/~/media/64511A895D86457E964174EDC5C4C7B1.PDF
Al-Sai, Zaher Ali, Rosni Abdullah, and Mohd Heikal Husin. “Critical success factors for big data: a systematic literature review.” IEEE Access 8 (2020): 118940-118956.
Ahmad, Norita, and Areeba Hamid. “Will Data Science Outrun the Data Scientist?.” Computer 56.2 (2023): 121-128.
https://www.knime.com/blog/anomaly-detection-predictive-maintenance-control-chart
https://prophet-analytics.de/norma_ai/

